numo-narray と benchmark_driver.gem
@watson1978 さんの blog で Mac 環境だと Linux 環境に比べて numo-narray が遅いというお話があったので調べてみました。
今回の比較では、先日の Rubyアソシエーション開発助成成果報告会 で発表されていた
@k0kubun さんの benchmark_driver.gem を使いました。
このベンチマークは、複数の Ruby バージョン間の比較や、同一 gem で複数のバージョン比較ができるという優れものです。
使い方は $ gem install benchmark_driver でインストールするだけです。
(rbenv を使用している場合、$ rbenv rehash で benchmark-driver コマンドを使用可能にする必要があります。)
グラフ画像を出力する場合は $ gem install benchmark_driver-output-gruff で追加の plugin をインストールします。 (要 RMagick)
確認環境
- CentOS 7.3(x86_64) / macOS Sierra(x86_64)
- Ruby 2.5.1
- benchmark_driver (0.14.3)
- benchmark_driver-output-gruff (0.3.1)
- numo-narray (0.9.1.2)
- numo-narray (0.9.9.0) ※ numo-narray の master の2018/7/11時点の最新 (inplace 演算と ブロードキャスト演算時の省メモリによる高速化対応版)を gem pkg にしたもの。
ベンチマーク内容
@watson1978 さんのベンチマーク結果をベースに inplace 演算と ブロードキャスト演算を加えて比較してみました。
$ cat numo_N_fp.yaml
contexts:
- gems: { numo-narray: 0.9.1.2 }
require: false
prelude: require 'numo/narray'
- gems: { numo-narray: 0.9.9.0 }
require: false
prelude: require 'numo/narray'
loop_count: 10000
prelude: |
N = 100000
xd = Numo::DFloat.new(N).seq
yd = Numo::DFloat.new(N).seq
xs = Numo::SFloat.new(N).seq
ys = Numo::SFloat.new(N).seq
benchmark:
'[100000] + [100000] (fp64)' : xd + yd
'[100000] + [100000] (fp32)' : xs + ys
'[100000].inplace + [100000] (fp64)': xd.inplace + yd
'[100000].inplace + [100000] (fp32)': xs.inplace + ys
'[100000] + 1 (fp64)' : xd + 1
'[100000] + 1 (fp32)' : xs + 1
'[100000].inplace + 1 (fp64)' : xd.inplace + 1
'[100000].inplace + 1 (fp32)' : xs.inplace + 1
- inplace 演算は指定した変数のメモリ領域を書き換える形で演算するため、結果的に省メモリになります。0.9.9.0(省メモリによる高速化版)で省メモリ化しています。
- ブロードキャスト演算は指定した変数を全要素に対して同じ計算(上記の場合は
+1)をします。0.9.9.0(省メモリによる高速化版)で省メモリ化しています。
上記を下記のように実行します。
$ benchmark-driver numo_N_fp.yaml --output markdown(Markdown 出力)$ benchmark-driver numo_N_fp.yaml --output gruff(PNG出力)
CentOS / macOS の結果 (グラフ)
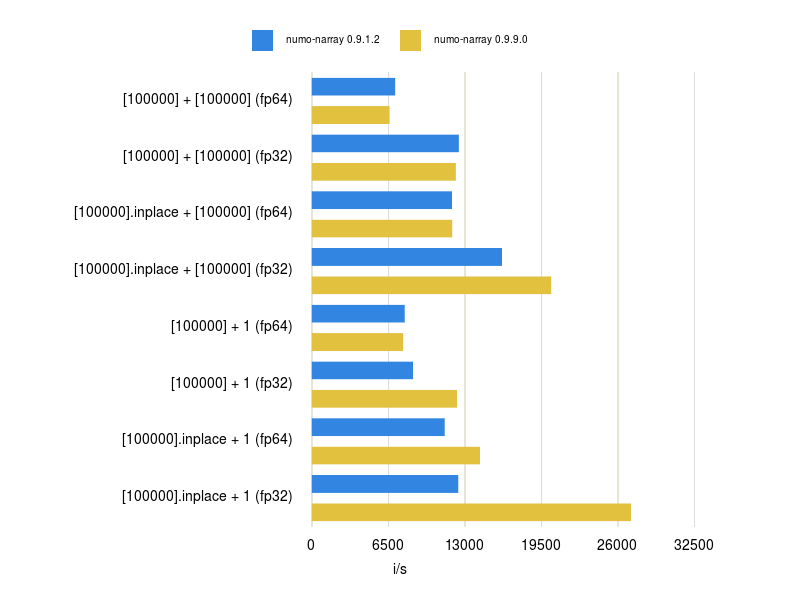
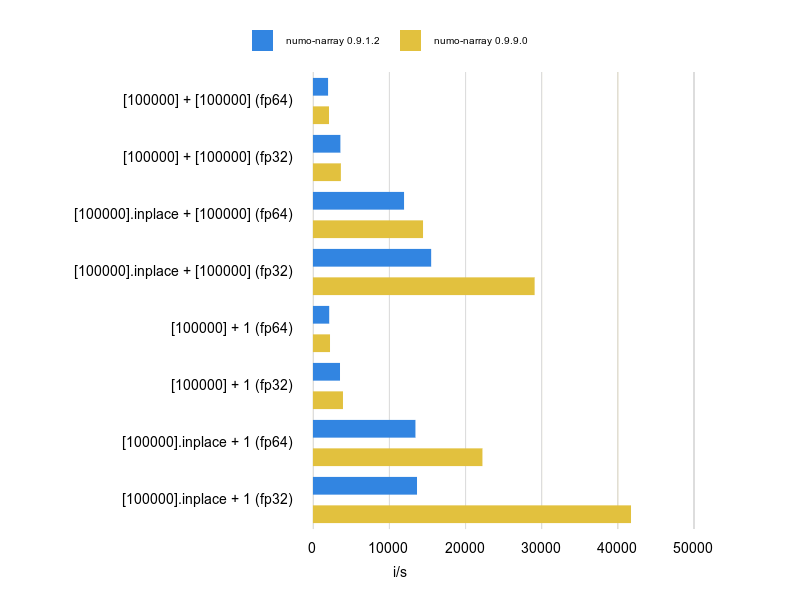
1秒間あたりの処理数 (i/s)なので、数値が大きい方が速いことを意味します。
- 通常演算(非inplace & 非broadcast)から inplaceやbroadcastに変更した場合、Linuxは1.5〜2倍速くなりますが、Macは4〜11倍速くなりLinuxより速い。
- サンプルソースを作成してアセンブラ出力を確認したところ、Mac はコンパイラ(Clang)が自動ベクトル(SIMD)化している。
CentOS 7 の結果 (数値) (※グラフ化とは別に再測定実施。)
| numo-narray 0.9.1.2 | numo-narray 0.9.9.0 | |
|---|---|---|
| [100000] + [100000] (fp64) | 7.150k | 7.040k |
| [100000] + [100000] (fp32) | 12.768k | 12.692k |
| [100000].inplace + [100000] (fp64) | 12.161k | 11.572k |
| [100000].inplace + [100000] (fp32) | 17.069k | 22.032k |
| [100000] + 1 (fp64) | 7.936k | 8.045k |
| [100000] + 1 (fp32) | 9.273k | 12.697k |
| [100000].inplace + 1 (fp64) | 11.570k | 14.160k |
| [100000].inplace + 1 (fp32) | 12.875k | 27.566k |
macOS Sierra の結果 (数値) (※グラフ化とは別に再測定実施。)
| numo-narray 0.9.1.2 | numo-narray 0.9.9.0 (master) | |
|---|---|---|
| [100000] + [100000] (fp64) | 1.897k | 1.829k |
| [100000] + [100000] (fp32) | 3.867k | 3.753k |
| [100000].inplace + [100000] (fp64) | 12.431k | 15.041k |
| [100000].inplace + [100000] (fp32) | 17.005k | 29.455k |
| [100000] + 1 (fp64) | 2.093k | 2.126k |
| [100000] + 1 (fp32) | 3.664k | 4.101k |
| [100000].inplace + 1 (fp64) | 13.843k | 23.250k |
| [100000].inplace + 1 (fp32) | 14.338k | 44.210k |
以上より、
というところでしょうか。
四則演算のベンチマーク (おまけ)
ついでに、RubyKaigi 2018 LT のベンチマーク結果を、非 inplace のケースも含めてbenchmark_driver.gem でベンチマーク化してみました。
ベンチマーク内容
$ cat broadcast_fp32.yaml
contexts:
- gems: { numo-narray: 0.9.1.2 }
require: false
prelude: require 'numo/narray'
- gems: { numo-narray: 0.9.9.0 }
require: false
prelude: require 'numo/narray'
loop_count: 5000
prelude: |
x = Numo::SFloat.ones([1000,784])
y = Numo::SFloat.ones([1000,784])
z = Numo::SFloat.ones([1000,1])
benchmark:
'[1000,784] + [1000,784]': x + y
'[1000,784].inplace + [1000,784]': x.inplace + y
'[1000,784] + [1000,1] ': x + z
'[1000,784].inplace + [1000,1] ': x.inplace + z
'[1000,784] + 1 ': x + 1
'[1000,784].inplace + 1 ': x.inplace + 1
'[1000,784] - [1000,784]': x - y
'[1000,784].inplace - [1000,784]': x.inplace - y
'[1000,784] - [1000,1] ': x - z
'[1000,784].inplace - [1000,1] ': x.inplace - z
'[1000,784] - 1 ': x - 1
'[1000,784].inplace - 1 ': x.inplace - 1
'[1000,784] * [1000,784]': x * y
'[1000,784].inplace * [1000,784]': x.inplace * y
'[1000,784] * [1000,1] ': x * z
'[1000,784].inplace * [1000,1] ': x.inplace * z
'[1000,784] * 1 ': x * 1
'[1000,784].inplace * 1 ': x.inplace * 1
'[1000,784] / [1000,784]': x / y
'[1000,784].inplace / [1000,784]': x.inplace / y
'[1000,784] / [1000,1] ': x / z
'[1000,784].inplace / [1000,1] ': x.inplace / z
'[1000,784] / 1 ': x / 1
'[1000,784].inplace / 1 ': x.inplace / 1
確認結果

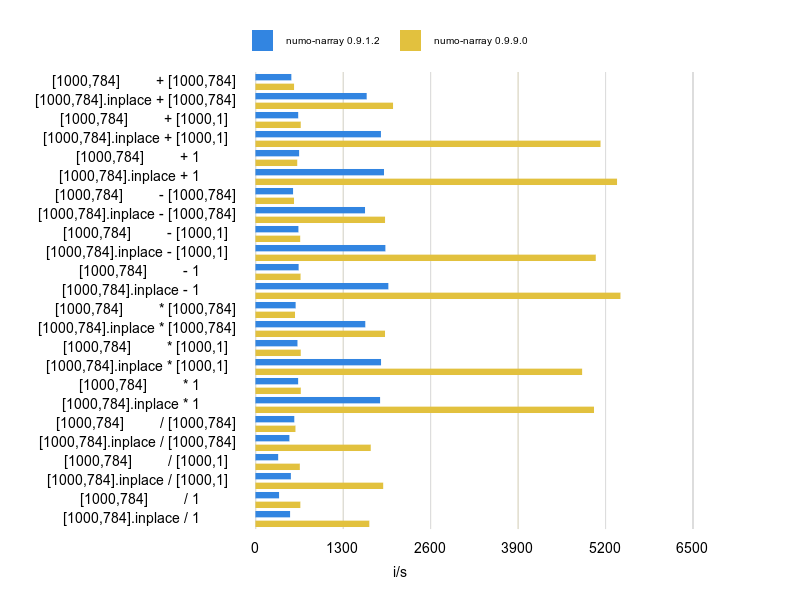
0.9.9.0(inplace 演算と ブロードキャスト演算時の省メモリによる高速化対応版)の改善効果がよくわかります。 同一gem で複数のバージョン比較ができる benchmark_driver.gem は便利ですね。